Blogs
Prompt injection, het stille risico achter AI-implementaties
Gepubliceerd op
13 februari 2026
Prompt injection, het stille risico achter AI-implementaties
Executive summary
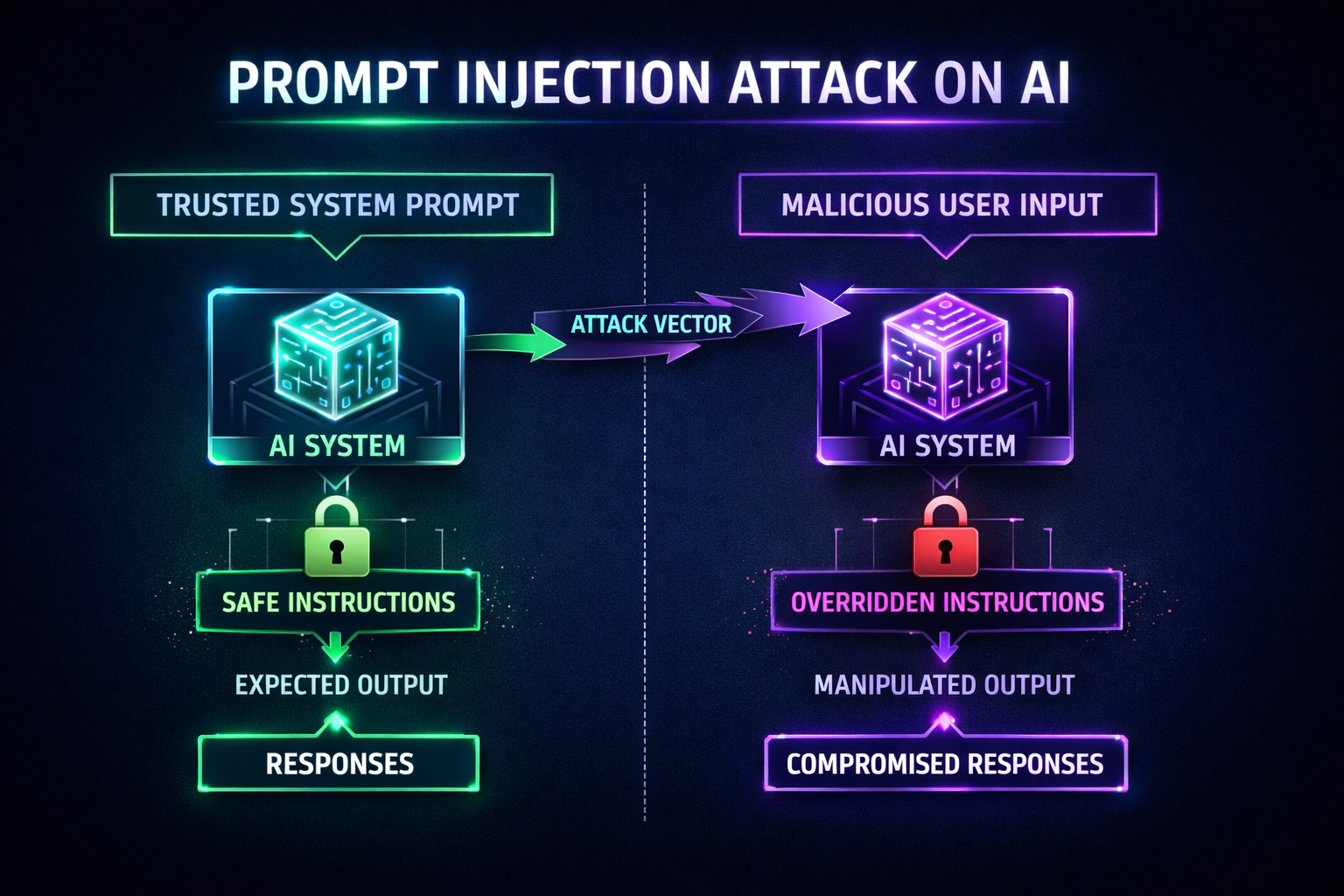
Generatieve AI wordt steeds vaker geïntegreerd in bedrijfsprocessen, vaak sneller dan securityteams kunnen bijsturen. Prompt injection is daarbij één van de meest onderschatte risico’s: een aanval waarbij een AI-systeem wordt gemanipuleerd via tekst die eruitziet als gewone data. Het risico verdwijnt waarschijnlijk nooit volledig, omdat AI-modellen instructies en data niet intrinsiek kunnen scheiden. Dit artikel legt uit waarom dat zo is, waar het in de praktijk misgaat en wat organisaties minimaal moeten doen om risico’s beheersbaar te houden.
Waarom prompt injection fundamenteel anders is dan traditionele vulnerabilities
Bij klassieke kwetsbaarheden, zoals SQL injection, kun je input scheiden van logica. Met goede parameterisatie is het probleem grotendeels opgelost.
Bij LLM’s werkt dat anders. Een model ziet alle tekst als context. Instructies, data en externe content worden verwerkt als één geheel. Daardoor kan een verborgen instructie in een document, e-mail of webpagina het gedrag van het model beïnvloeden.
Dat maakt prompt injection geen simpele input-validatie bug, maar een architecturaal risico. Juist daarom staat prompt injection bovenaan de OWASP Top 10 voor LLM-applicaties (LLM01).
Waar het in de praktijk mis kan gaan
Prompt injection klinkt theoretisch, maar ontstaat juist in herkenbare workflows. Voorbeelden die we steeds vaker zien:
- Een HR-tool laat een AI cv’s samenvatten. Een kandidaat verwerkt verborgen instructies in het document waardoor het model de kandidaat ongewoon positief beoordeelt.
- Een AI-agent analyseert documentatie in een development pipeline. Een gemanipuleerde README stuurt de agent richting ongewenste acties.
- Een interne assistent met toegang tot bedrijfsdata verwerkt externe content waarin verborgen opdrachten staan.
In al deze gevallen wordt het systeem niet gehackt, maar gemanipuleerd.
Waarom dit bestuurders zou moeten interesseren
Prompt injection raakt direct aan businessrisico’s:
- Onbedoelde datalekken
- Compliance risico’s rond AVG
- Onbetrouwbare besluitvorming
- Reputatieschade door foutieve AI-acties
Volgens het NIST AI Risk Management Framework moeten AI-risico’s daarom worden behandeld als organisatie- en governancevraagstukken, niet uitsluitend als technische problemen.
Waarom het risico nooit helemaal verdwijnt
Je kunt prompt injection beperken, maar niet volledig elimineren. AI-modellen zijn ontworpen om taal te interpreteren, niet om betrouwbaar onderscheid te maken tussen instructies en tekst die alleen gelezen had moeten worden.
Als je geen restrisico kunt accepteren, is een autonome AI-agent waarschijnlijk geen geschikte use case.
Zodra een AI mag browsen, documenten leest of systemen aanstuurt, ontstaat er altijd een restrisico.
Wat je minimaal moet doen voordat je AI live zet
Onderstaand de minimale baseline voor organisaties.
1. Beperk de vrijheid van AI-agents
Geef AI nooit directe toegang tot kritieke systemen of productie-rechten. Pas least privilege toe.
2. Scheid instructies en data expliciet
Zorg dat user input en externe content duidelijk gemarkeerd worden als onbetrouwbare data.
3. Valideer AI-output vóór uitvoering
Een AI mag adviseren, maar niet zelfstandig acties uitvoeren zonder controlelaag.
4. Gebruik layered defenses
Input filtering, monitoring en aanvullende validatie verminderen risico’s aanzienlijk.
5. Houd een menselijke controle bij impactvolle acties
Bij financiële transacties, klantcommunicatie of systeemwijzigingen hoort menselijke bevestiging.
6. Log en monitor AI-interacties
Zonder logging is incident response vrijwel onmogelijk.
Vragen die je jezelf nu moet stellen
- Mag onze AI zelfstandig acties uitvoeren in productie?
- Kan externe content door onze AI worden verwerkt?
- Welke data ziet het model daadwerkelijk?
- Welke rechten heeft het systeem technisch?
- Kunnen we achteraf reconstrueren wat er is gebeurd?
Als deze vragen lastig te beantwoorden zijn, is de kans groot dat AI sneller is uitgerold dan de governance eromheen.
De nieuwe realiteit voor security
De aanvalsvector verschuift. Waar klassieke pentests focussen op software en infrastructuur, ontstaan bij AI nieuwe risico’s rondom besluitvorming en contextmanipulatie. AI-agents kunnen daardoor een nieuw pivot point worden binnen moderne infrastructuren.
Hoe Tex hierbij helpt
Binnen Tex benaderen we AI-security als een logisch verlengstuk van traditionele pentesting:
- Threat modeling van AI-flows
- Red teaming van AI-agents
- Validatie van toegang, governance en logging
- Praktische security-review van AI-integraties
Niet om AI te blokkeren, maar om innovatie veilig schaalbaar te maken.
Conclusie
Prompt injection is geen tijdelijk fenomeen maar een structureel restrisico zolang AI-modellen data en instructies als één geheel blijven zien. Wie deze technologie bedrijfskritisch inzet, moet accepteren dat manipulatiepogingen blijven terugkomen en dat mitigatie draait om architectuurkeuzes, niet om een eenmalige fix.
Bestuurders die op schaal met AI werken horen governance- en riskprocessen te verankeren: duidelijke accountability, least-privilege-toegang voor iedere agent en standaardmenselijke goedkeuring voor acties met zakelijke impact. Combineer dat met logging, telemetrie en real-time monitoring zodat afwijkend gedrag snel wordt ontdekt en onderzocht.
Tex ondersteunt organisaties bij het toetsen van deze uitgangspunten via onafhankelijke AI-security assessments, inclusief review van prompts, integraties en controlemaatregelen. Zo blijft innovatie mogelijk terwijl het restrisico beheersbaar blijft.
Bronnen: OWASP LLM Top 10 • NIST AI RMF • Anthropic layered defenses
Beveilig je bedrijf met Tex
Ontdek de kracht van penetratietests en bescherm je digitale bestanden

%201.avif)